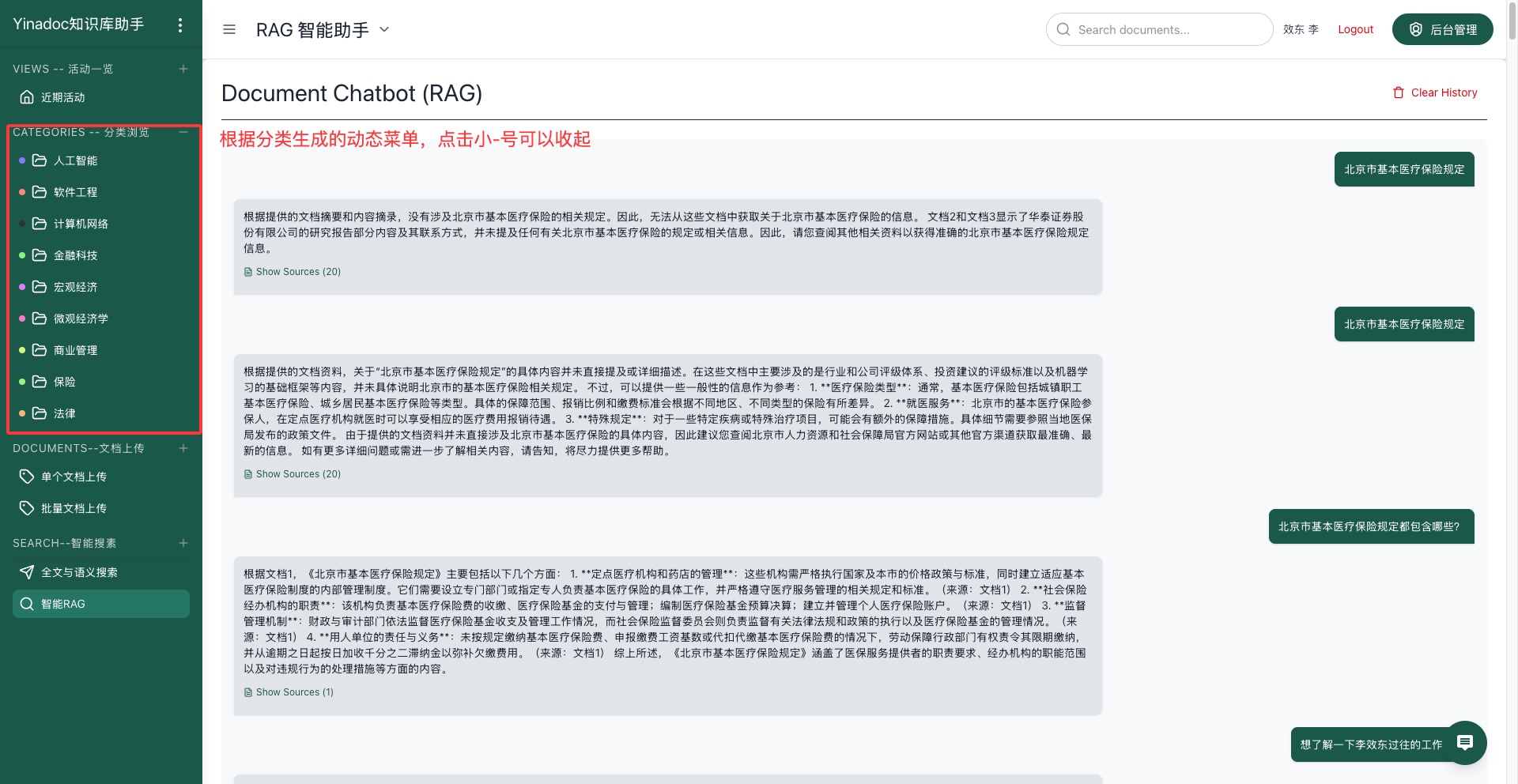
LLM驱动的知识库助手系统
Yinadoc 是一款 AI 驱动知识库助手,它能够将企业所累积的文档、文件、合同等等,真正数字化为知识资产,赋能企业的运营和日常管理。 Yinadoc 充分挖掘、利用和结合开源系统优秀的、前沿的文档处理、智能搜索功能和先进的 RAG(检索增强生成)技术。 该系统在文档理解和上下文答案生成方面提供了前所未有的准确性,使其成为智能企业搜索和知识发现领域的一个新生力量。
Click to enlarge
🚀 核心技术创新
1. Elasticsearch 作为系统骨干
市场优势: 企业级可扩展性和性能
- 统一搜索架构: 单一平台处理文档索引、向量存储和元数据管理
- 水平扩展性: 处理 PB 级文档集合,查询响应时间在毫秒级
- 高可用性: 内置集群和复制功能确保 99.9%正常运行时间
- 实时索引: 文档在摄取后几秒内即可搜索
- 高级查询功能: 支持复杂的布尔、模糊和语义搜索操作
2. Unstructured.io 集成的高级文档处理
市场优势: 卓越的文档理解和数据提取
- 通用文档支持: 处理 50 多种文件格式,包括 PDF、Word 文档、PowerPoint、图像和复杂布局
- 智能布局检测: 保留文档结构、标题、表格和关系
- 高级表格提取: 保持表格数据完整性与列/行关系
- 图像和图表处理: 从嵌入图像和图表中提取文本和数据
- 元数据保留: 保留关键文档元数据以增强可搜索性
- 语言识别: 自动识别和处理多语言文档
3. Ollama-Qwen (Qwen2.5-70B) RAG 引擎
市场优势: 最先进的对话式 AI 与企业安全
- 大型语言模型卓越性: 700 亿参数模型提供人类般的推理和理解能力
- 本地化部署: 完整的数据主权和安全合规性
- 上下文答案生成: 综合多个文档信息提供全面回答
- 多轮对话: 在复杂对话会话中保持上下文
- 领域特定微调: 适应组织特定术语和知识模式
- 成本效益: 消除与基于云的 LLM 服务相关的按查询 API 成本
⚡ 技术性能优势
搜索性能
- 100 毫秒以下响应时间: 优化的 Elasticsearch 查询与智能缓存
- 并发用户支持: 处理 1000 多个同时用户而不影响性能
- 智能排序: 结合语义相似性、相关性评分和用户权限
- 自动完成: 实时搜索建议与错字容错
文档处理速度
- 并行处理: 多线程文档摄取管道
- 批量操作: 高效处理大型文档集合
- 增量更新: 仅处理更改内容以实现更快更新
- 处理吞吐量: 每小时处理 10,000 多个文档的能力
RAG 响应质量
- 上下文感知答案: 利用多个相关文档提供全面回答
- 来源归属: 每个答案都包含可追溯的来源参考
- 事实准确性: 基于事实的回答减少幻觉风险
- 可定制推理: 可调节的温度和上下文窗口设置
🛡️ 企业安全与合规
数据主权
- 本地化部署: 完全控制敏感企业数据
- 空气隔离操作: 可在无互联网连接的情况下运行
- GDPR/CCPA 合规: 内置数据保护和隐私控制
- 审计跟踪: 全面记录所有用户交互和系统操作
高级访问控制
- 基于角色的权限: 细粒度文档和功能访问控制
- 企业身份验证: LDAP/Active Directory 集成
- 动态内容过滤: 搜索操作期间的实时权限检查
- 安全令牌管理: 基于 JWT 的身份验证,可配置过期时间
💼 市场竞争优势
相比传统搜索平台(SharePoint、Confluence)
- ✅ 语义理解: 超越关键词匹配,理解上下文和意图
- ✅ 对话式界面: 自然语言查询 vs 复杂搜索语法
- ✅ 跨平台集成: 跨多个内容存储库的统一搜索
- ✅ AI 生成摘要: 无需阅读整个文档即可获得即时洞察
相比基于云的 AI 解决方案(Microsoft Copilot、Google Bard)
- ✅ 数据隐私: 数据不离开您的基础设施
- ✅ 成本可预测性: 无按查询收费或基于使用量的定价
- ✅ 定制化: 完全控制 AI 模型行为和训练
- ✅ 离线能力: 无需互联网连接即可运行
相比开源替代方案
- ✅ 企业支持: 专业支持和维护服务
- ✅ 集成解决方案: 预配置、测试和优化的组件
- ✅ 安全加固: 开箱即用的企业级安全配置
- ✅ 可扩展性测试: 针对企业工作负载验证的性能
📈 商业价值主张
生产力提升
- 75%减少 查找相关信息的时间
- 60%减少 因更好的知识发现而产生的重复工作
- 90%更快 的智能知识辅助入职培训
- 50%减少 通过自助服务功能减少的支持工单量
成本效益
- 零按查询成本: 可预测的基于基础设施的定价
- 减少培训需求: 直观的自然语言界面
- 降低 IT 开销: 统一平台减少系统复杂性
- 合规效率: 自动化审计跟踪和数据治理
创新加速
- 更快决策制定: 即时访问相关历史知识
- 跨团队协作: 打破信息孤岛
- 知识保留: 捕获和保存机构知识
- 持续学习: 系统随使用模式改进
🔧 技术规格
系统要求
- 最低硬件: 32GB 内存,8 个 CPU 核心,1TB SSD 存储
- 推荐硬件: 128GB 内存,24 个 CPU 核心,10TB NVMe 存储
- 操作系统: Linux(Ubuntu 20.04+,CentOS 8+,RHEL 8+)
- 容器支持: Docker,Kubernetes 就绪
集成能力
- REST API: 用于自定义集成的全面 API
- Webhook 支持: 实时通知和事件触发器
- SAML/OAuth2: 企业身份提供商集成
- 数据库连接器: 与 SQL/NoSQL 数据库直接集成
监控与维护
- 健康仪表板: 实时系统性能监控
- 自动备份: 可配置的备份计划和保留策略
- 日志分析: 全面的审计和性能日志
- 警报系统: 带有可定制阈值的主动监控
🎯 目标市场细分
主要市场
- 大型企业(10,000+员工)具有复杂知识库
- 政府机构 需要本地化、安全的文档处理
- 医疗机构 需要符合 HIPAA 标准的知识管理
- 金融服务 具有严格的数据主权要求
- 律师事务所 处理大量复杂文档
使用案例
- 客户支持: 即时访问产品文档和故障排除指南
- 合规性: 快速检索政策、程序和监管文档
- 研发: 交叉引用技术文档和研究论文
- 销售支持: 快速访问竞争情报和产品信息
- 培训与入职: 为新员工提供交互式知识发现
🚀 路线图与未来增强
近期(3-6 个月)
- 多模态搜索: 支持音频和视频内容分析
- 高级分析: 用户行为和知识缺口分析
- 移动应用: 原生 iOS 和 Android 应用
- API 扩展: GraphQL 和流式 API 支持
长期(6-12 个月)
- 联邦搜索: 跨多个外部知识库查询
- 自动分类: ML 驱动的文档分类和标记
- 预测分析: 基于用户模式预测信息需求
- 知识图谱: 文档和概念之间关系的可视化映射
结论
我们的 AI 驱动知识库助手系统代表了企业知识管理的范式转变,结合了 Elasticsearch 的稳健性、Unstructured.io 的高级文档处理能力和 Ollama-Qwen 的对话式 AI 能力。这种独特的组合在保持完整数据主权和成本可预测性的同时,提供了无与伦比的性能、安全性和用户体验。
该系统有望在快速增长的企业 AI 市场中占据重要市场份额,为优先考虑数据隐私、安全性和控制的组织提供云端解决方案的有力替代方案。